
Stable Diffusion
SDXL Prompts 進階指南 (1) - 鏡頭視角距離
SDXL 版本的 prompts 鏡頭距離視角教學,可以單純使用 prompts 就控制鏡頭距離視角,而不用 ControlNet 或其他 extensions。同時也新增場景構圖 prompts 以供參考。

Stable Diffusion
SDXL 版本的 prompts 鏡頭距離視角教學,可以單純使用 prompts 就控制鏡頭距離視角,而不用 ControlNet 或其他 extensions。同時也新增場景構圖 prompts 以供參考。

Stable Diffusion
今個月依然是消息量極高的一個月,希望 CEO 離去一事不會令 Stable Diffusion 從此消失就好了。當然還有大量新 Model 推出才是最令人感動興奮的事!

Stable Diffusion
在 Meta open source 推出 Llama 3 後,很多相關的應用程式都應運而生,現在最常用的 ComfyUI 及 Automatic1111/forge 都有可以使用 Llama 3 來豐富你的 prompts,而且不用擔心複雜的操作,因為已經有相關 extensions 推出,只需簡單的安裝過程即可使用。
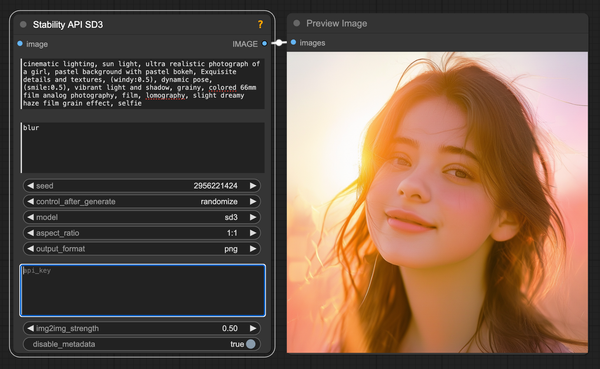
Stable Diffusion
在 Stable Diffusion 3 推出 API 後,雖然我也有介紹過用 Colab 連接 Stable Diffusion 3 API 的方法,但是習慣做用本地生成工具的大家也許不習慣做用 Colab,所以就為大家帶來 ComfyUI 的做用方法。

Stable Diffusion
Stable Diffusion WebUI 1.9 終於可以分開選 sampling method 跟 schedule type,也有各方面的修正及改善,馬上來看看有什麼更新!

Stable Diffusion
萬眾期待的 Stable Diffusion 3,日前已經在 Stability AI Developer Platform API 以 API 搶先發佈,看來跟傳聞一樣未必會以 open source 形式公開。

Stable Diffusion
Stability AI 又推出一款新的 Checkpoint Model - Cos Stable Diffusion XL,Cos 的意思就是 Cosine-Continuous。其中最大賣點就是 Cos Stable Diffusion XL Edit 版整,使用這個 Checkpoint Model 以全新的方法去進行 inpaint,不用落 mask,不用 controlnet,直接用 prompt 就可以做到 inpaint 效果!

Stable Diffusion
有時想知道一張相片應該用什麼文字來形容,這張圖片可能是來自 Midjourney、Stable Diffusion,Photoshop 繪畫的圖片或是相機拍攝的真實相片,雖然 Stable Diffusion 的圖片可以憑 infotext 去讀取 prompts,但經過轉存或壓縮的圖片也可能遺失 infotext,這時候我們可以用什麼方法取得 prompts?
Google Analytics
雖然很久沒寫技術文章,但有讀者向我問能否用之前所教的方法應用在 GA4。以下是我之前講述在本地使用 Google 的 analytics.js 來避開 CSP 的封鎖。

Stable Diffusion
Stability AI 宣布發布其最新模型 Stable Video 3D (SV3D),專為渲染 3D 影片而設計。 SV3D 在先前 Stable Video Diffusion 的基礎上引入了新的深度,能夠從單一影像輸入建立和轉換多視圖 3D 視訊。

Stable Diffusion
終於迎來 Automatic1111 Stable Diffusion WebUI v1.80 ,今次更新也新增了不少有用的功能,我們馬上來看看有什麼重點的更新!

Stable Diffusion
過去一個月可精彩了,多個重量級 Model 連環推出,Stable Diffusion 經過加速後,就再次增加畫質及對文字理解能力的大型 Model,每隔一兩個月就大幅提升,而且次次都充滿驚喜!

Stable Diffusion
對很多 Stable Diffusion 的用家來說,有時候生成的圖片總是很不太好看,想要的原素都有齊了,但畫質不夠高。也有常常使用 SD 1.5 可以生成優質圖片的用家,在轉成 SDXL 後生成的人像圖片質量總是不好,其實有一些 prompts 加上後會對畫質有大大幫助!

Stable Diffusion
Stable Diffusion 3的早期預覽終於揭開神秘面紗。這款新型文本轉圖像模型承諾在多主題提示、圖像質量和拼寫能力等方面實現顯著改進,被認為是人工智慧技術的重大飛躍。

Stable Diffusion
在 2023 年底 SDXL Turbo 才首次亮相。不足三個月一個更優秀和更迅速的 SDXL Lightning 閃電般誕生。這款創新模型能夠在短時間內生成優質圖像,提供從 1 到 8 步的選擇。再跟 LoRA 和 Unet 進行整合,SDXL Lightning 使用家能夠以閃電般的效率生成圖像。

Stable Diffusion
Stable Cascade 是一個全新的 Text to Image Model,引入了引人注目的三階段方法,為質量、靈活性、微調和效率設立了新的標準。它優先考慮消除硬件障礙,旨在提高各種指標的性能。