Fooocus 再度進化,新模式新功能
現在幾乎是我最喜歡的 Stable Diffusion 軟件,剛剛更新到最新版本 2.1.824 還沒有到 2.2 但已經加入很多強大的功能,並一直與 Midjourney 看齊。


現在幾乎是我最喜歡的 Stable Diffusion 軟件,剛剛更新到最新版本 2.1.824 還沒有到 2.2 但已經加入很多強大的功能,並一直與 Midjourney 看齊。
更新程式
- 先使用指令
git pull取得最新版本。 - 使用指令
python entry_with_update.py啟動同時進行更新。
Newer models and configs are available. Download and update files? [Y/n]- 系統會問你是否更新及下載再新 Model。按
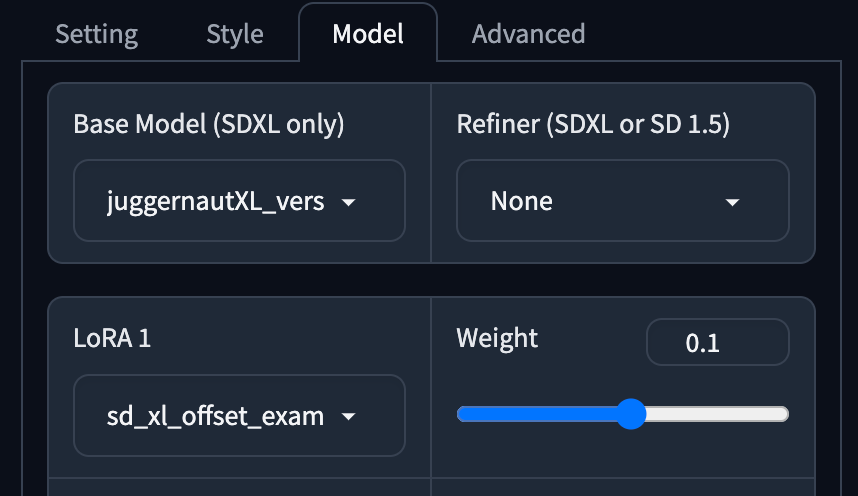
Y確定就會開始更新更下載新 Model。 - 這次更新會預設下載 Juggrnaut XL v6 取代 原生 SDXL v1 Model 以取得更好效果,此 Model 生成歐美真人相當有真實感,值得推薦使用。
- 由 Fooocus v2.1.60 開始支援不同的啟動模式。
- 如果目標是生成動漫人物的話,可以使用
python entry_with_update.py --preset anime作為啟動指令,Windows 用戶可以用run_anime.bat啟動程式,那麼預設下載的 Model 會改為 blue Pencil XL 。並會下載 DreamShaper v8 作為 refiner model 及 unaesthetic XL v3.1 為其 embeddings,原來可以用 1.5 Model 來作 refiner 使用。 - 既然有生成動漫人物專用的指令,當然也提供了生成真實人物的指令,使用
python entry_with_update.py --preset realistic作為啟動指令,Windows 用戶可以以用run_realistic.bat啟動程式,就會下載 Realistic Stock Photo v1 作為 Model,名符其實此款 Model 可生成貌似 Stock Photo 的相片。另外還會下載 SDXL Film Photography Style 作 LoRA 取代 SDXL Offset 並會用直倒896 x 1152生成圖片。
測試三個模式
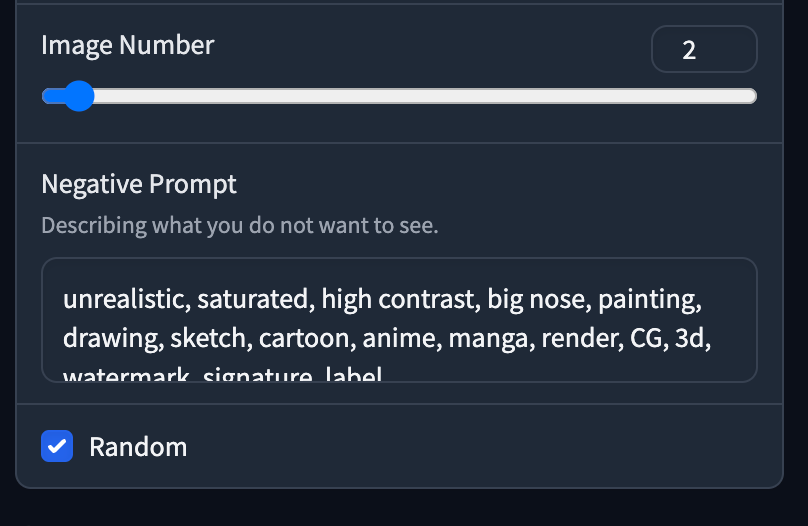
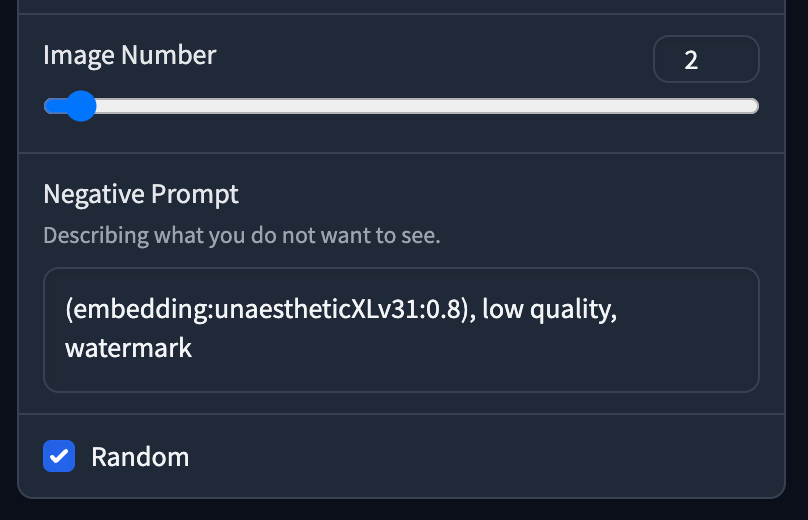
把東西都下載好後,接下來就試試看預設模式下三個設定生成出來的圖片有什麼分別! Prompt 為 1girl 及 ginger cat 。
預設模式
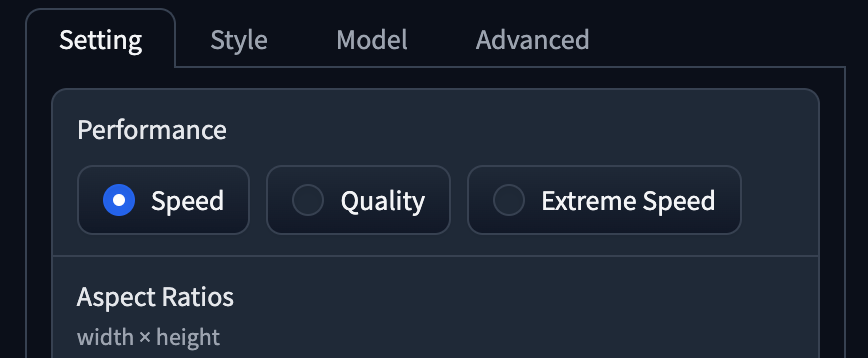
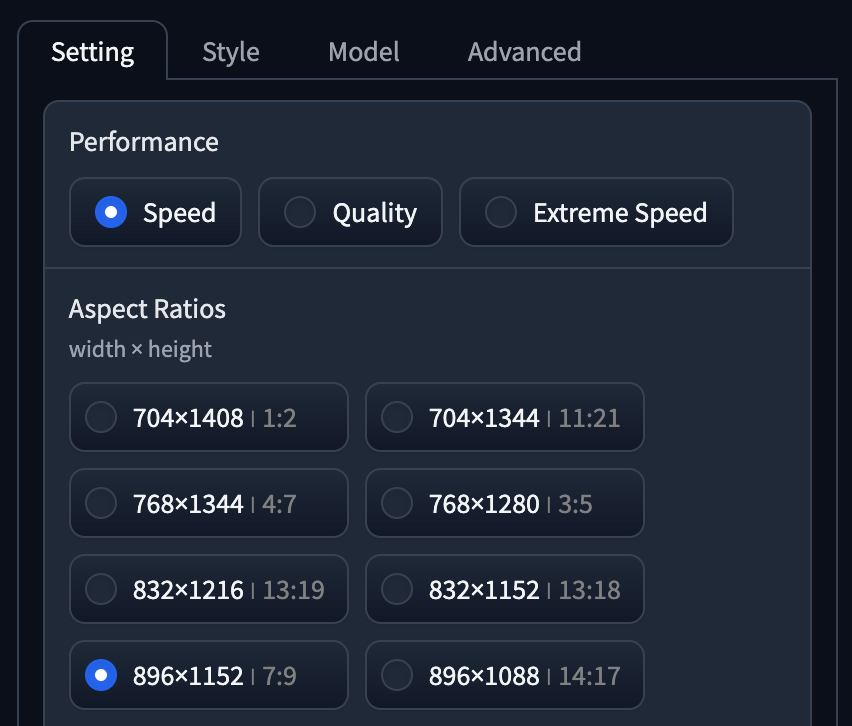
- Performance 為 Speed,長闊大預為
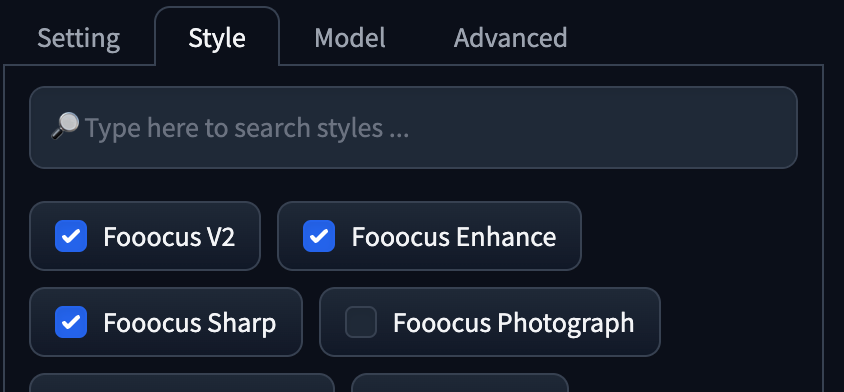
1152 x 896。 - Style 同時使用了
Fooocus V2,Fooocus Enhance,Fooocus Sharp。 - Base Mode 使用 Juggernaut XL
v6,沒有使用 refiner。 - LoRA 使用了 SDXL Offset。
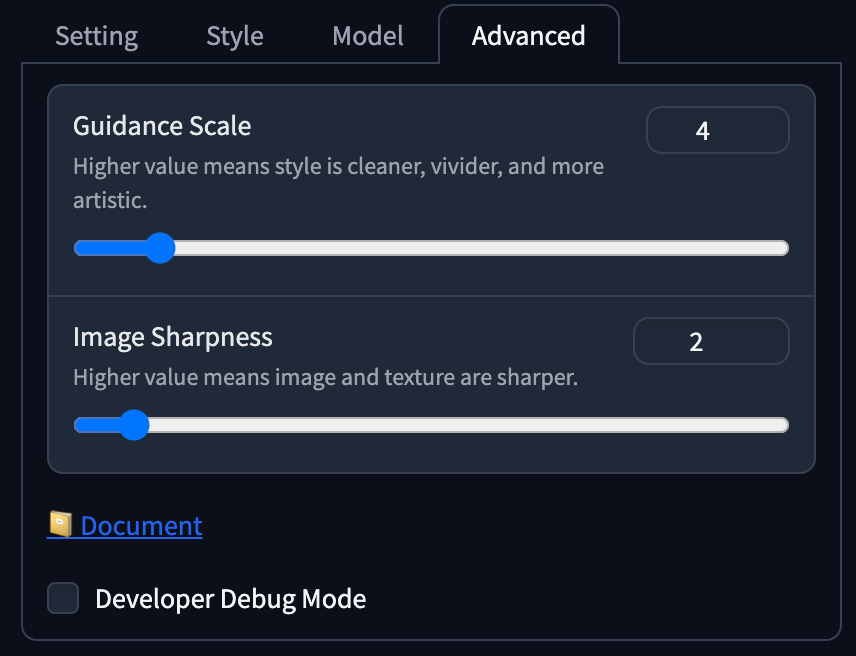
- Guidance Scale 設定為
4,Image Sharpness 設定為2。


1girl出來多數是歐美女性的樣子,真實感高,色調偏黃,有專業攝影的感覺。


ginger cat真貓一樣,貓毛偏長(?),環境光還是偏黃,對比高很高,毛髮精細度也很高!
寫實模式預設設定
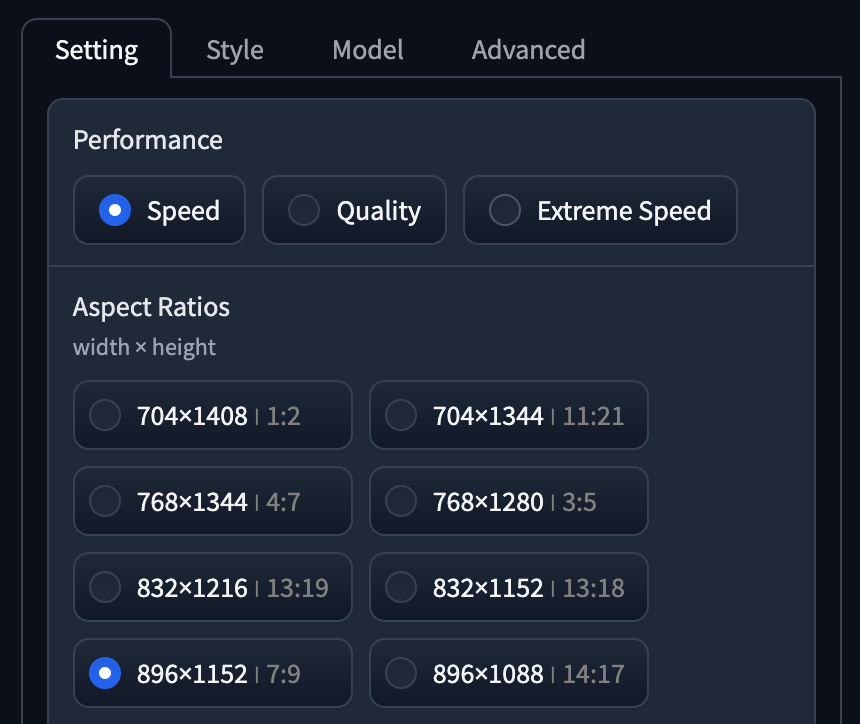
- Performance 為 Speed,長闊大預為
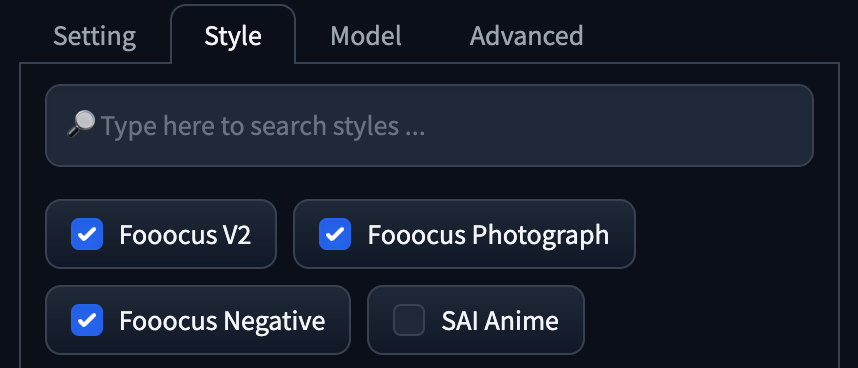
896 x 1152。 - Style 同時使用了
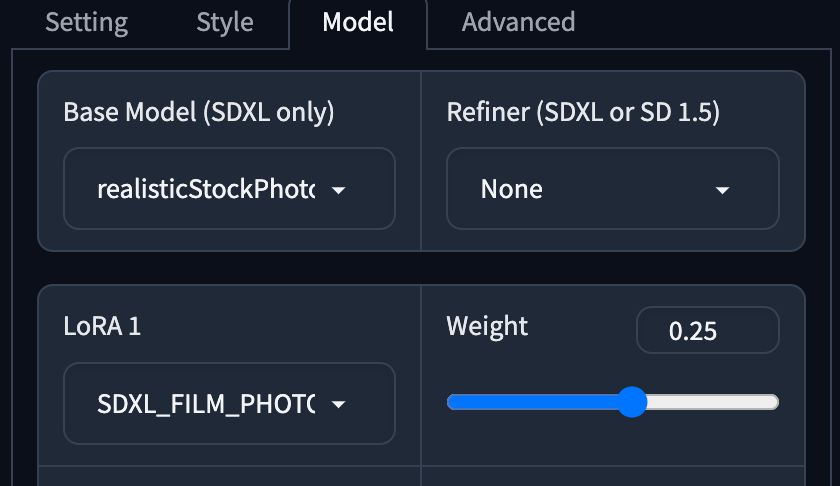
Fooocus V2,Fooocus Photograph,Fooocus Negative。 - Base Model 使用了 Realistic Stock Photo
v1,沒有使用 Refiner。 - LoRA 使用了 SDXL Film Photography Style 。
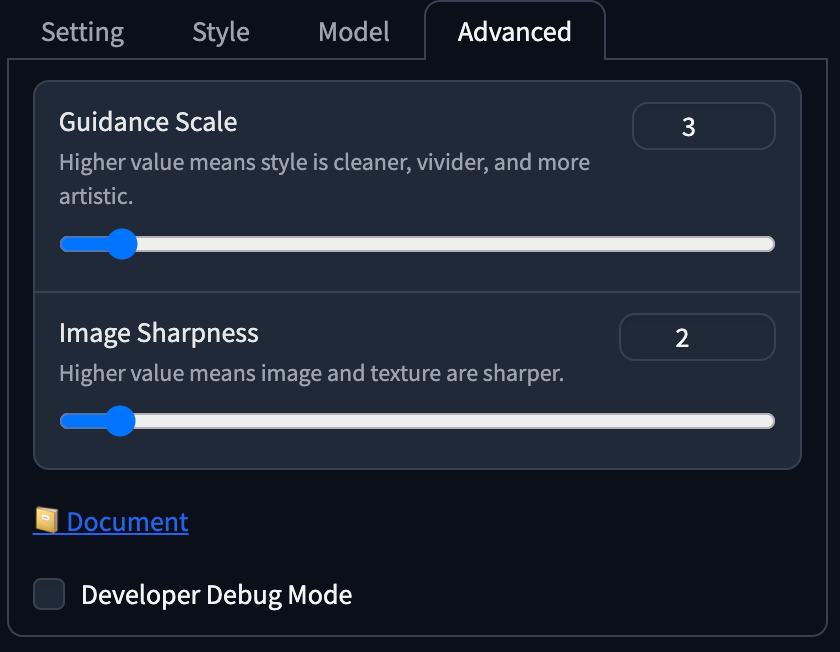
- Guidance Scale 設定為
3,Image Sharpness 設定為2。


1girl出來有日系女孩的樣子,色調偏藍有用菲林相機拍照的感覺。


ginger cat還是很可愛的貓貓,景深相當強,色調較柔和,對比度也比較低。
動漫模式預設設定
- Performance 為 Speed,長闊大預為
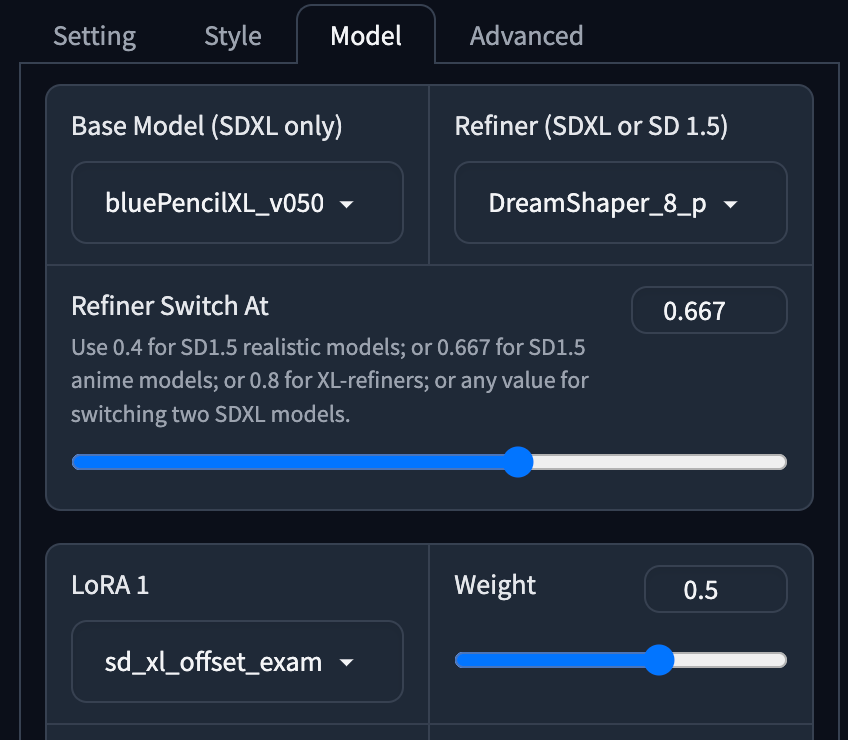
896 x 1152。 - Negative Prompt 中使用了 unaesthetic XL
v3.1。 - Base Model 使用了 bluePencil XL
v5。 - Refiner Model 使用了 DreamShaper
v8。 - LoRA 使用了 SDXL offset 。
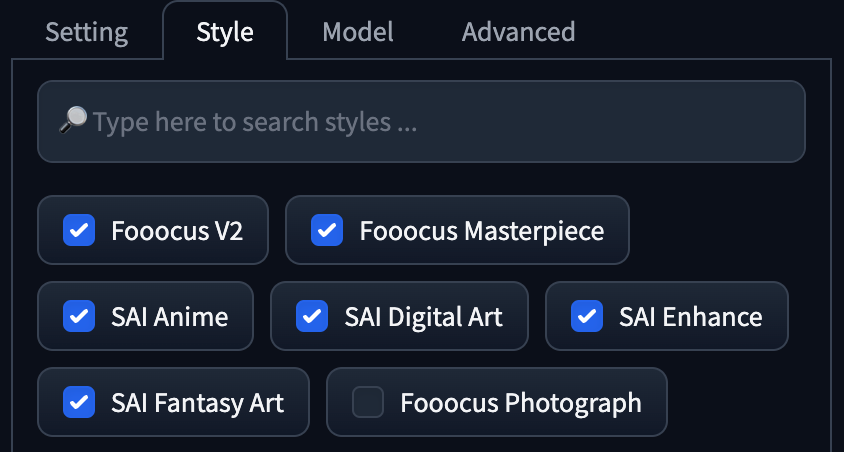
- Style 同時使用了
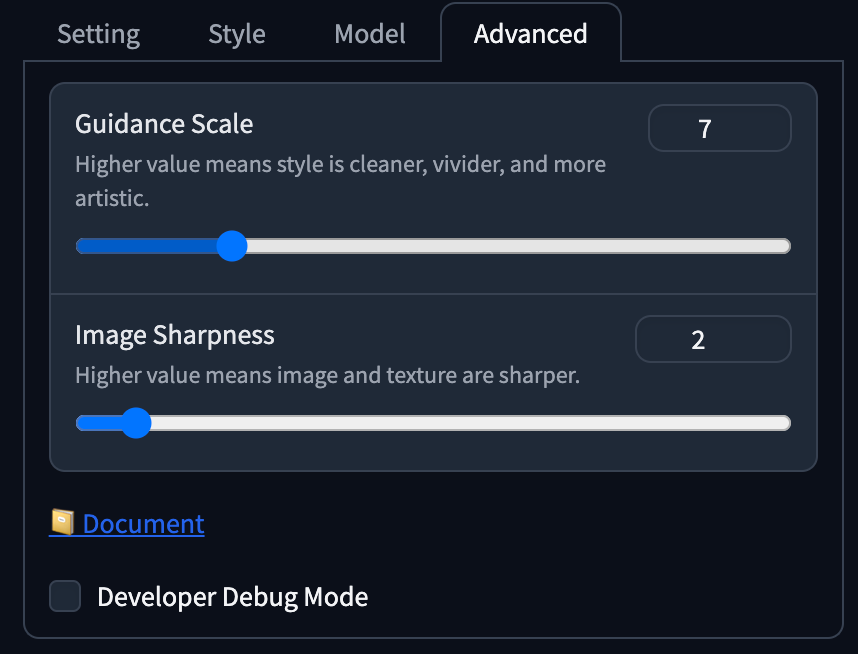
Fooocus V2,Fooocus Masterpiece,SAI Anime,SAI Digital Art,SAI Enhance,SAI Fantasy Art。 - Guidance Scale 為
7,Image Sharpness 為2。


1girl都有些中國風的建築背景,人物的服飾也有些中國元素,色調柔和有些平塗的感覺。


ginger cat長毛風格的貓貓,顏色亮麗畫風也很平易近人。
極速模式
在最近 LCM 及 SDXL Turbo 推動高速化生成,Fooocus 當然也有提供極速模式,在 Performance 選取 Extreme Speed 模式,開始生成前會自動下載 SDXL LCM LoRA,同時會鎖定了 Advanced 中的 Guidance Scale 及 Image Sharpness 設定。同時生成步數會大幅減少至 8 。
以下是預設模式 Extreme Speed 下生成的圖片:




雖然解像度明顯下解了不少,但整體上的成果還是比 Stable Diffusion WebUI +LCM 優秀,相信 Fooocus V2 的 prompt 幫上了不少忙,速度上即使沒有快至 1 秒完成,但也比 Speed Mode 快上幾倍,對電腦比較慢的用家有很大幫助!
Fooocus Styles
- 之前的 Default (Slightly Cinematic) 改成 Fooocus Cinematic。
- 新增 Fooocus Sharp 來改善 SDXL 的模糊及增加銳利度。
- 新增 Fooocus Enhance 來自 Juggernaut XL 預設的 negative prompts 來改善圖片的質素。
- 將原本預設的 Default (Slightly Cinematic) 改成 Fooocus Sharp, Fooocus Enhance 及 Fooocus V2 。
- 現在選取了的 Style 會排到最高。
Image Prompt
就像 Stable Diffusion 使用 IP-Adapter 一樣可以跟據輸入的圖片去生成圖片,不過一些生圖的原則就有點不一樣,反而跟 Midjourney 的 Image Prompt 相似。
以下圖表比較三者的分別:
| Midjourney | Ip-Adapter | Fooocus | |
| 文字Prompt | 與圖片 Prompt 混合 | 多數會無視文字 Prompt | 與圖片 Prompt 混合 |
| 使用多張圖片 | 維持畫質 | 畫質下降 | 維持畫質 |
| 單圖輸入失敗 |
輸出無關連但 維持高畫質的圖片 |
輸出有關連但 低畫質的圖片 |
輸出無關連但 維持高畫質的圖片 |
| 多圖輸入失敗 |
無視無效的圖片 維持高畫質的圖片 |
輸出有關連但 低畫質的圖片 |
無視無效的圖片 維持高畫質的圖片 |
| 畫質影響 | 輸入圖片對畫質無影響 |
輸入低質圖片會 影響輸出圖片畫質 |
輸入圖片對畫質幾乎無影響 |
| 結果變化 | 輸入圖片後仍然有變化 | 變化較少 | 輸入圖片後仍然有變化 |
測試使用
首先打開 Input Image 選取 Image Prompt,最少選取一張最多可以同時選取四張圖片做 Reference ,選取底部的 Advanced 可以調整更多細節。
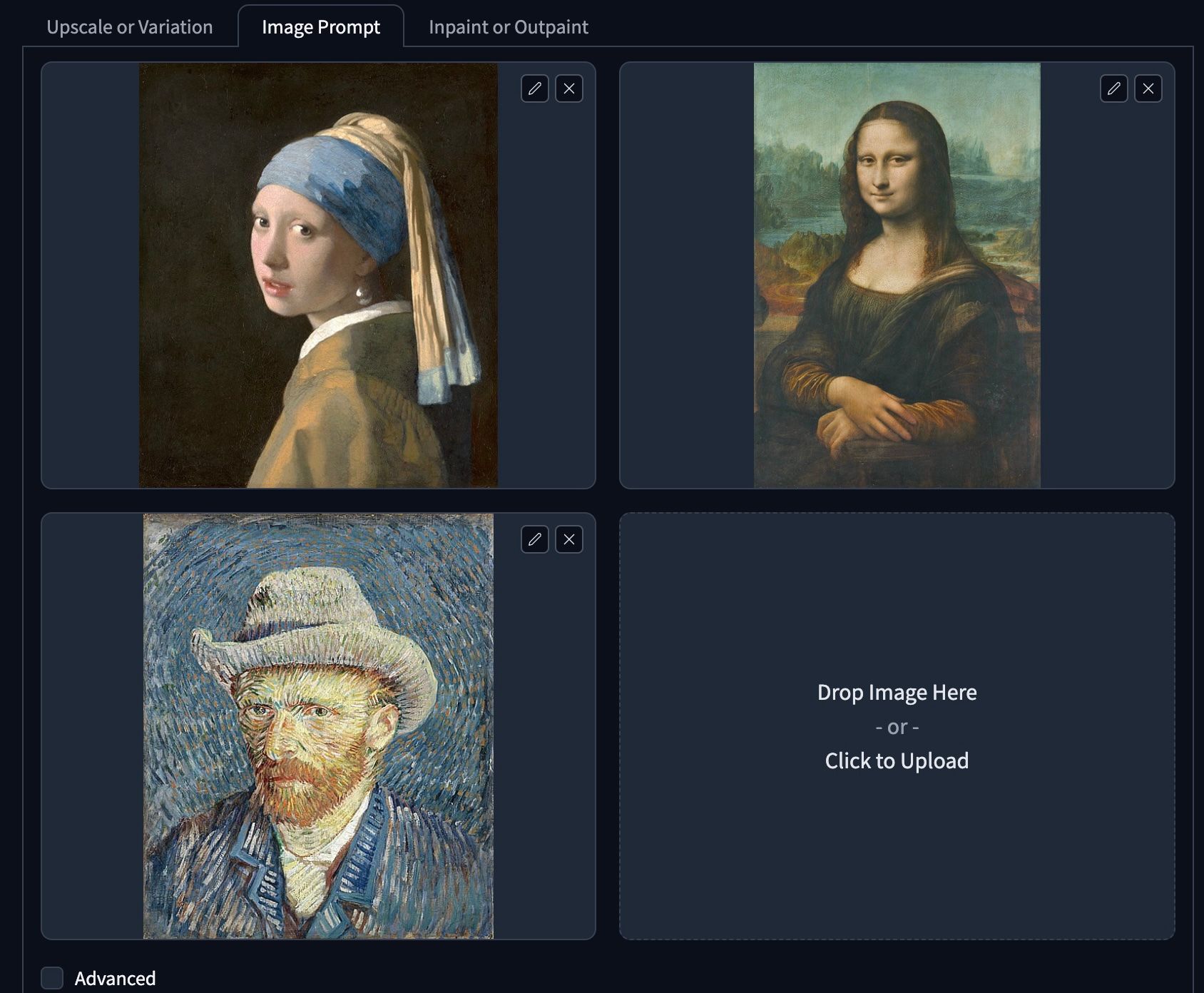
- 首先以三張名畫做 Image Prompt 。
- Performance 使用 Speed。
- Prompt:
1girl。 - Style 選取
Fooocus v2,Fooocus Enhance及Fooocus Sharp。 - Base Model 使用原生 SDXL 以免變成真人/動漫人物,Refiner Model 使用原生 SDXL Refiner。
- 一次生成兩張
1152 x 896看看效果如何。 - 首次使用 Image Prompt 又要下載一些 Model。


接下來打開 Advanced Mode 來試試不同 Model 下的作用。
Prompt: 1girl, new york street
ImagePrompt
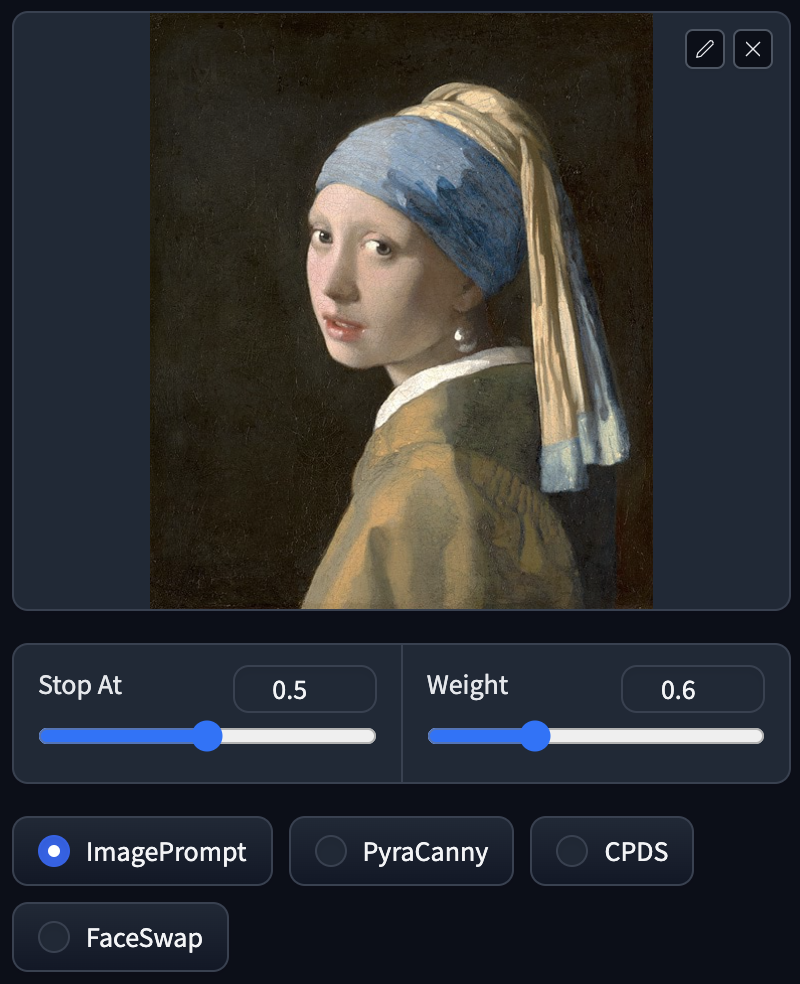

將畫作真人化,大概保留了顏色及各種元素(白人,頭巾,衣著,耳環),此功能就是分析圖像將其當成 prompt 使用生成圖片。
PyraCanny
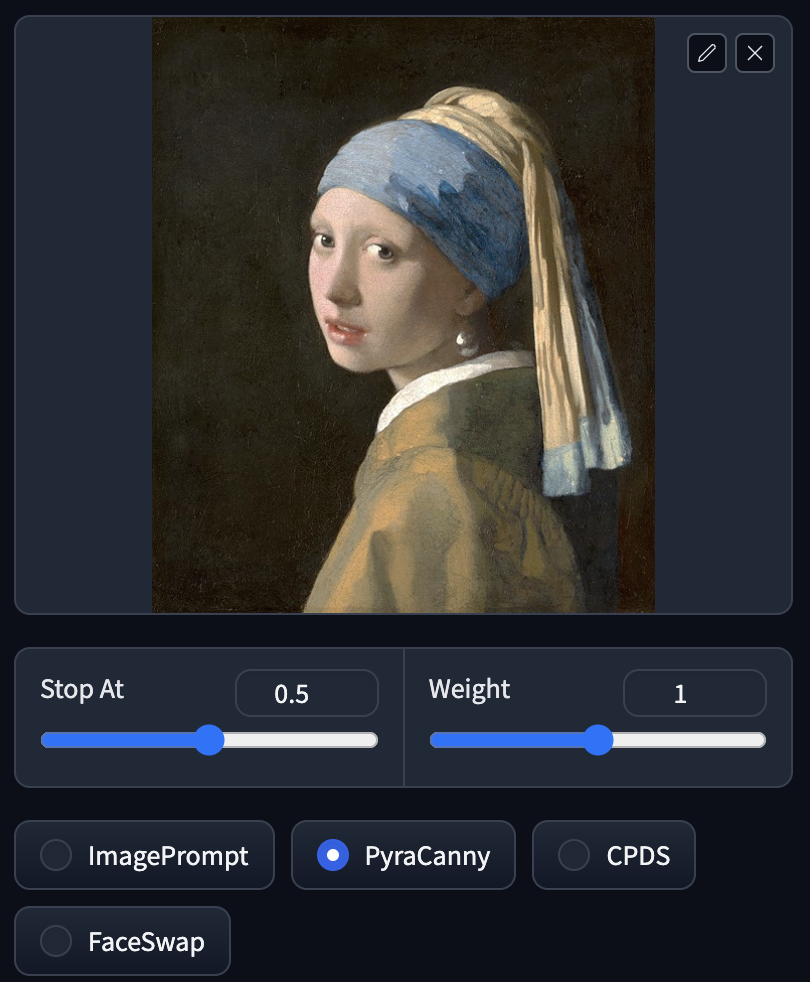

PyraCanny 就像 ControlNet 的 Canny 差不多,幾圖片線條化再依照外框生成圖片,所以可以保留圖片外型,但入面的顏色就要靠 prompt 去決定。
CPDS
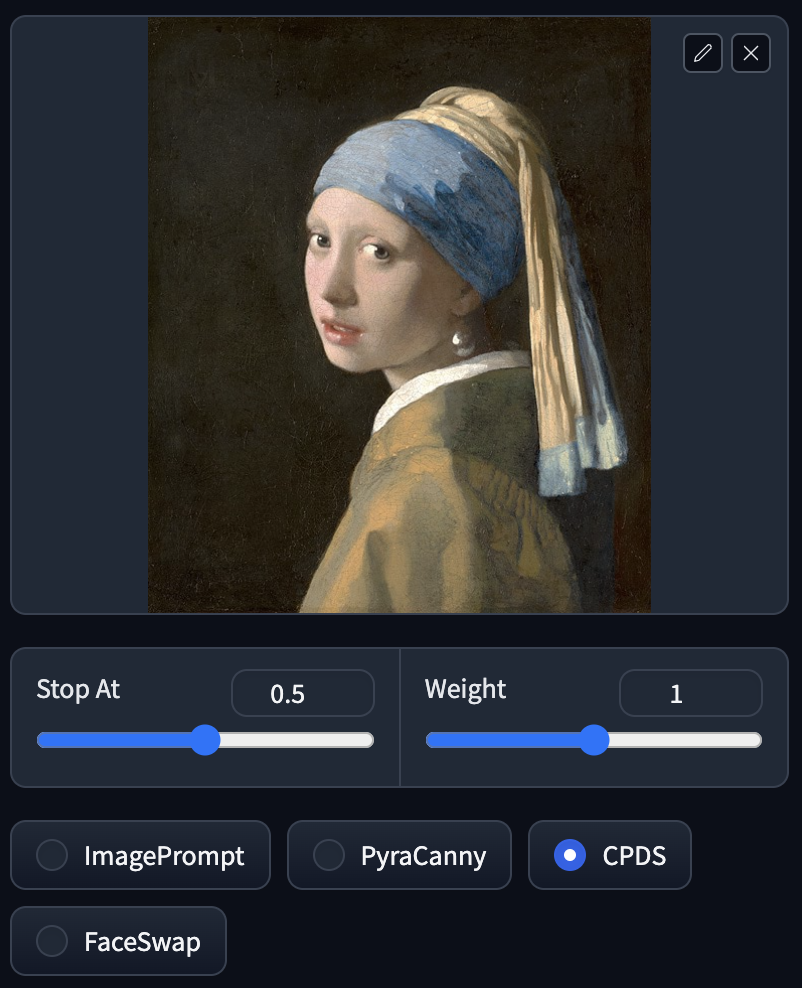

CPDS 全寫是 Contrast Preserving Decolorization,簡單來說就是黑白化同時保持對比度,出來的結果比起 PyraCanny 跟原圖的線條沒這麼相似,但也保持一定外型。
FaceSwap
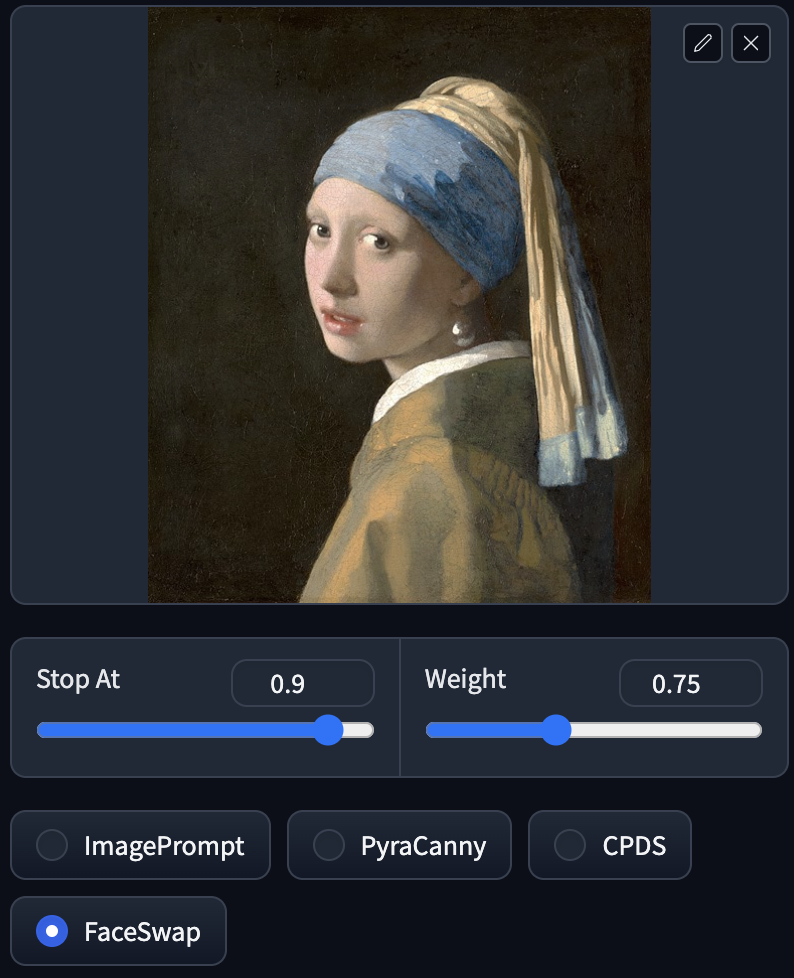

FaceSwap 名符其實就是換臉,將圖片的人臉換上跟據你 prompt 生成的圖片上,樣子會跟原圖比較接近。
由於 Fooocus 新功能推出太快,所以介紹得有點遲,現在功能越來越強勁,加上 LCM 等快速生成技術,令 Fooocus 馬上進化到超越 Midjourney 了。