在 ComfyUI 上使用 SDXL 1.0
在 Stable Diffusion SDXL 1.0 版本推出以來,受到大家熱烈喜愛。我也在多日測試後,決定暫時轉投 ComfyUI。


在 Stable Diffusion SDXL 1.0 版本推出以來,受到大家熱烈喜愛。我也在多日測試後,決定暫時轉投 ComfyUI。原因如下:
- ComfyUI 可以一次過設定整個流程,對 SDXL 先要用 base model 再用 refiner model 的流程節省很多設定時間。
- ComfyUI 啟動速度比較快,在生成時也感覺快一點,特別是用 refiner 的時候。
- ComfyUI 整個界面非常自由,可以隨意拖拉到自己喜歡的樣子。
- ComfyUI 在設計上很像 Blender 的 texture 工具,用後覺得也很不錯。
- 學習新的技術總令人興奮,是時候走出 StableDiffusionWebUI 的舒適圈。
下載 SDXL 1.0
首先當然要下載 SDXL 1.0 的 Checkpoint Model,由於 SDXL 在訓練時圖片用上了 1024 x 1024 的圖片,解像度比 SD 1.5 時大了足足一整倍,而且訓練數據也增加了3倍,所以最終出來的 Checkpoint File 也比 1.5 的大得多。
下載 SDXL base Model (6.94GB)

下載 SDXL refiner Model (6.08GB)

另外可以下載 SDXL 用的 VAE (335MB)

安裝方法
基本上跟 StableDiffusionWebUI 相似,安裝 Homebrew 及 Python 的方法可以參考前一篇文章,如已安裝可以跳過。
 Edmond Yip
Edmond Yip
- 安裝 Python 後,開新資料夾叫 ComfyUI 就好了,打開 Terminal 輸入指令
git clone https://github.com/comfyanonymous/ComfyUI.git把 ComfyUI 儲存到資料夾中。 - 安裝最新版的 torch
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu- 再安裝所需文件
pip install -r requirements.txt - 然後就可以使用指令啟動 ComfyUI
python main.py --force-fp16 - 成功運行後在 http://127.0.0.1:8188/ 就可以見到 ComfyUI。
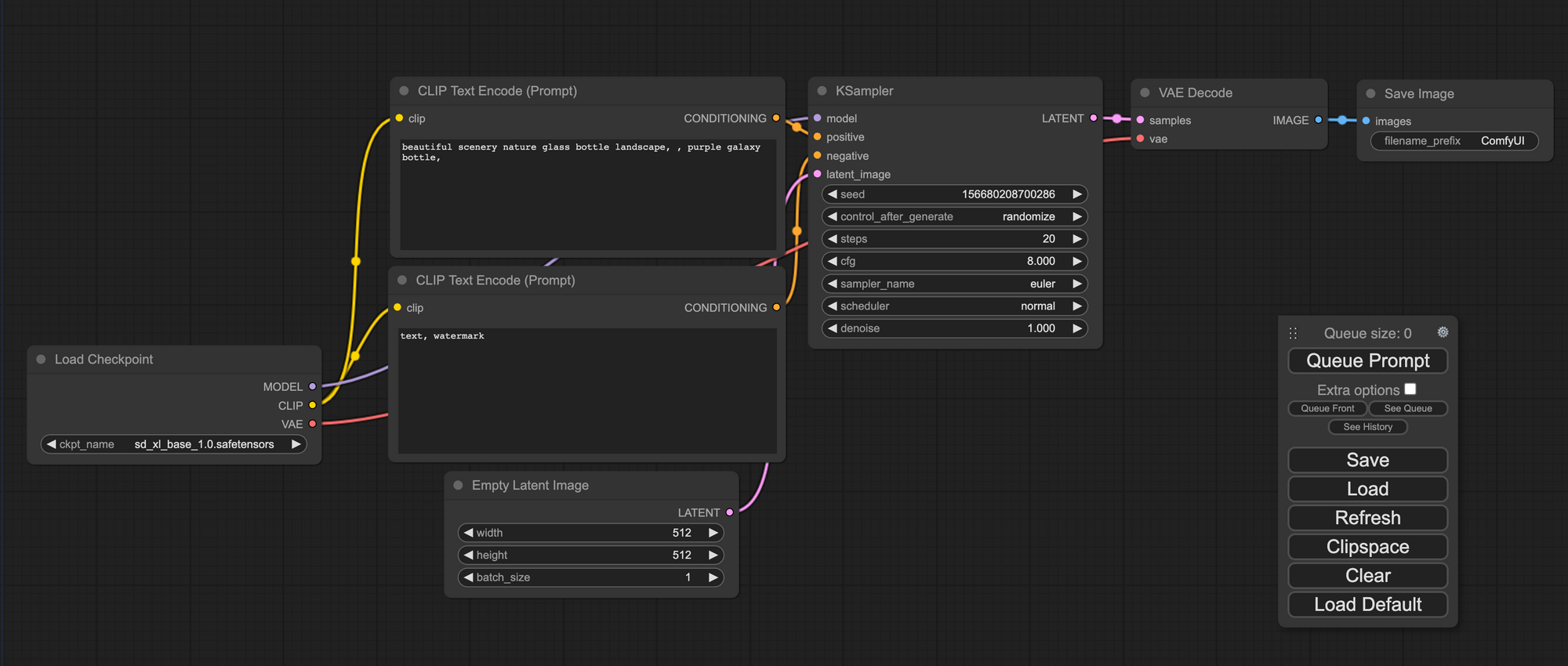
使用方法
界面看起來很厲害,其實沒這麼困難的。首先把下載了的 checkpoint model 放到 /ComfyUI/models/checkpoints/ 中,Vae 放到 /ComfyUI/models/vae/,按一下右邊 Queue Prompt 下面的 Refresh 就會自動讀到新增的 models。
每一個小方格我們都叫做一個 Node,由最左邊的 Load Checkpoint 開始運作。
- Load Checkpoint - 讀取 checkpoint model,這裡選
sd_xl_base_1.0.safetensors作為 model。 - 然後 Node 右邊的 3 條線就是將這個 Node 的結果輸出到另一個 Node。
- Clip Text Encode 就是輸入 Prompt 及 Negative prompt 的 Node,Checkpoint Loader 經 Clip Text Encode 將 prompt 傳送 KSampler。
- Latent Image 就是用作設定長闊以及每批次生成圖片的數量, SDXL 長闊記得設定成
1024 x 1024。 - KSampler 入面的設定有用過 StableDiffusionWebUI 都很熟悉,seed 就是種子,使用相同設定及相同的種子就可以生成相同的圖片。還有預設每次生成後都會隨機變動 seed,這樣就每次都會生成不同的圖片。
- Step 是步數,通常設定 20 - 50,少過 20 步的過圖片會不成形,太多就會花很多時間及生成多餘的東西。CFG 是 prompts 的影響力,越大就越確實依照 prompts 生成,設定得比較少的話生成出來的圖片會比較有創意,最好由 7 - 15 左右。 Sampler 跟 Schedular 加起來就是 StableDiffusionWebUI 的 Sampling Methods,我最常用的
DPM++ SDE Karras就是dpmpp_sde+karras。 - 最後右邊的 Save Image 就是自動儲存生成起的圖片。
- 選好了 Model ,輸入了 prompts 及選好設定後就可以按
Queue Prompt開始生成。 - 然後生成的過程會一個 Node 一個 Node 去顯示整個過程去到那一步,直到最後就會在 Save Image 顯示預覽圖。
用了以下 Prompt
Intricate dynamic action shot of An astronaut riding a white horse on moon, highly detailed, anime style, studio anime, vibrant color
及 Negative Prompt
(low quality, worst quality:1.2), embedding:negativeXL.safetensors, watermark, photo, deformed, black and white, realism, disfigured, low contrast
用動畫風格來生成了一個經典的太空人。
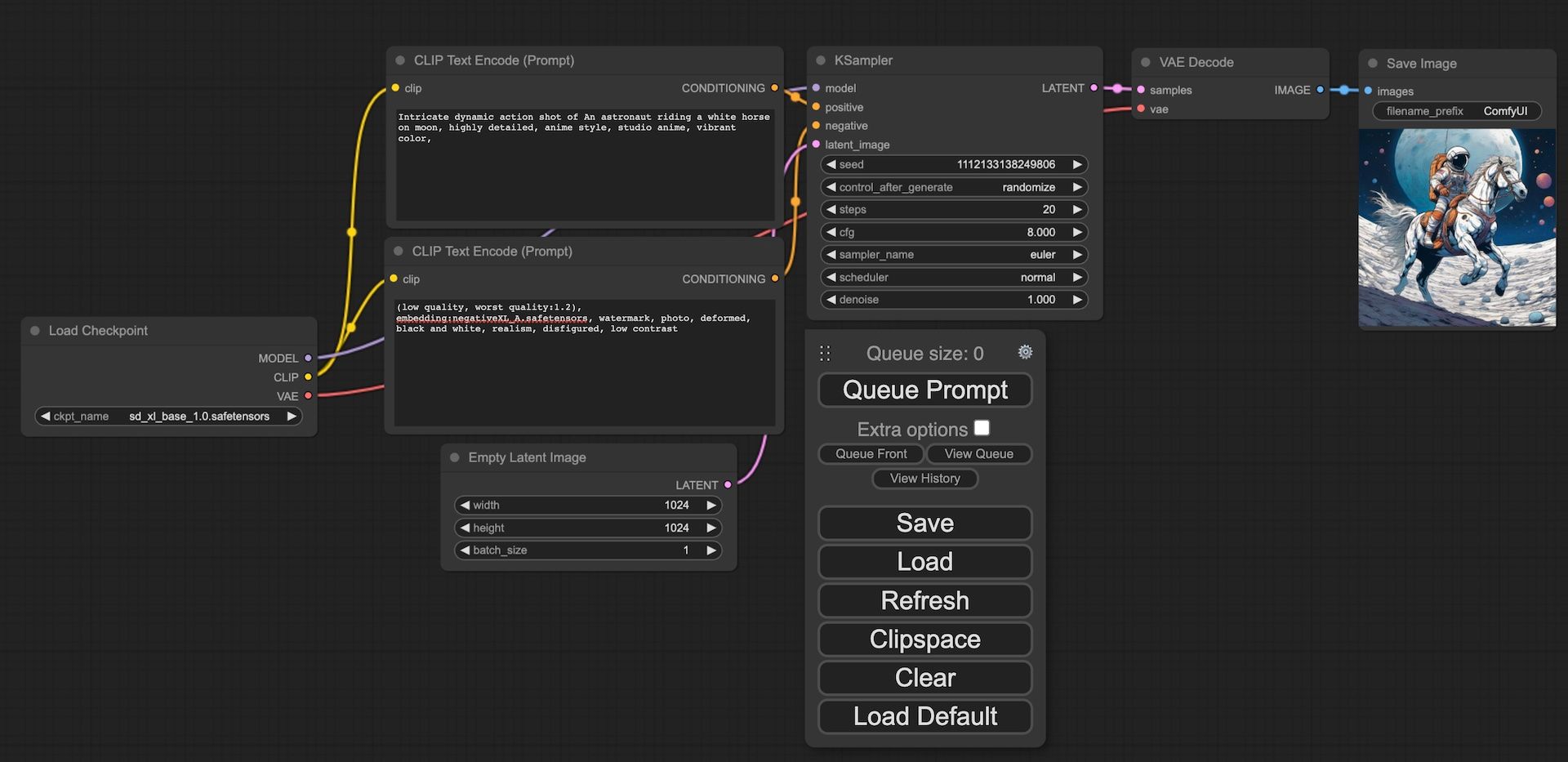

不過生成後就會覺得出來的圖片怪怪的,精細度沒想像中高,很多像草稿的線條,主體邊緣解像度也有點低,而且 Refiner Checkpoint 不是還沒用過嗎,Refiner 就是用來在 base 生成圖片後再進行一次 img2img 細化 base 生成的如果,可以提高解像度及改善模糊的位置。
SDXL 1.0 的 ComfyUI 基本設定
我先設定用一個比較簡單的 Workflow 來用 base 生成及用 refiner 重繪。
- 需要有兩個 Checkpoint loader,一個是 base,另一個是 refiner。
- 需要有兩個 Sampler,一樣是一個是 base,另一個是 refiner。
- 當然 Save Image 也要兩個,一個是 base,另一個是 refiner。
- 然後就是要將整個 workflow 設定先用 base 文生圖,然後用將圖每給 refiner 圖生圖。
- 只要一個 queue 即可輸出 Base 及 Refiner 兩張圖,方便用來比較結果。
由於時間關係,我已經準備好檔案以供下載:
下載檔案後只要在 Queue Prompt 下按 Load 再選擇檔案即可有相同的界面設定,只要放好 Checkpoint Model 檔案即可。
Negative Prompt
如果有留意 Negative prompt 中有句 embedding:negativeXL.safetensors ,只要下載檔案放到 /COMFYUI/models/embeddings/ ,在 negative prompt 中用 embedding: + file name 就可以。

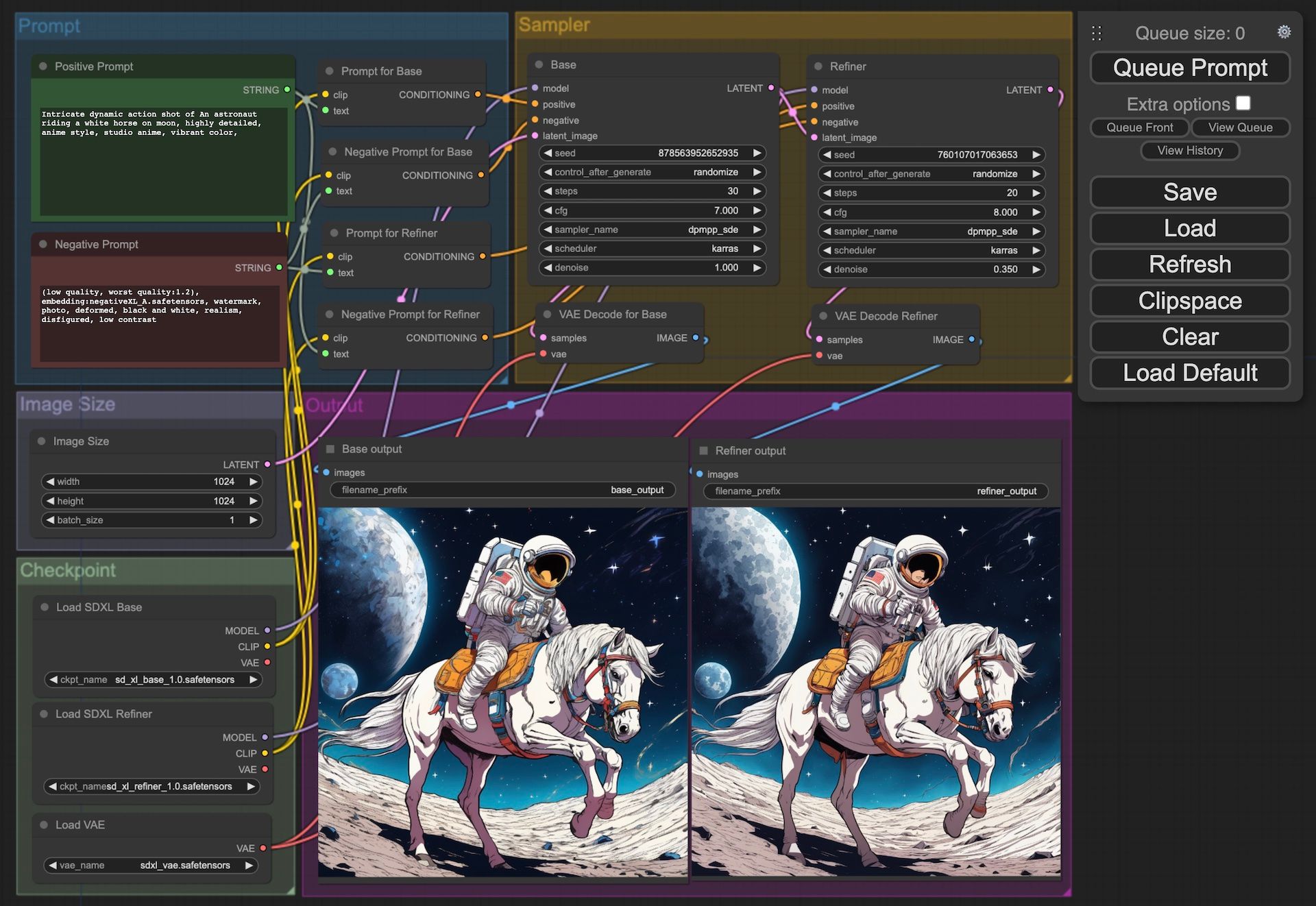
- 左上角的 Prompt Group 內有 Prompt 及 Negative Prompt 是 String Node,再分別連到 Base 及 Refiner 的 Sampler。
- 左邊中間的 Image Size 就是用來設定圖片大小,
1024 x 1024就是對了。 - 左下角的 Checkpoint 分別是 SDXL base, SDXL Refiner 及 Vae。
- 右上的 Sampler 分別是 SDXL Base 及 SDXL Refiner 的設定及 Vae Decode。
- 最後會生成左邊的是 base 的圖片,右邊是 refiner 的圖片。


比較一下 base 及 refiner 出來的成果:
- 線條較為結實,比較少雜線。
- 背面的星球的表面也比較好。
- 馬的面部線條都簡化了。
ComfyUI 用後感
不過 ComfyUI 還有不少需要改進的空間,比起 StableDiffusionWebUI 真的比較難用。但在多線程的工作上也有他的好處,因為可以同時有很多組 prompt / checkpoint / LoRA ,同一時間運算比較不同的設定也有其好處,以後或者雙修 ComfyUI 及 StableDiffusionWebUI。



