使用 LoRA 極速四步生成圖片
平時用 Stable Diffusion 生成圖片時很多時間都用於等待,但現在 Latent Consistency Models ( LCM ) 推出了一個可以大幅削減生成時間的 LoRA,克服一般 Latent Diffusion models ( LDM ) 緩慢的生成過程,令好像 Stable Diffusion 這類預訓練的 LDM 實現以超少的步數完成生圖過程。


平時用 Stable Diffusion 生成圖片時很多時間都用於等待,但現在 Latent Consistency Models ( LCM ) 推出了一個可以大幅削減生成時間的 LoRA,克服一般 Latent Diffusion models ( LDM ) 緩慢的生成過程,令好像 Stable Diffusion 這類預訓練的 LDM 實現以超少的步數完成生圖過程。

如何使用?
最重要是這種技術是已經可以在 Stable Diffusion WebUI 中使用,最簡單的方法就是使用 LoRA 版本,既可以直接使用原本在用的 Checkpoint 及 Extension,也可以達到加速的效果。
首先可以下載 LMC 的 LoRA,有分 1.5 及 SDXL 版本

SD 1.5

SDXL
由於兩個檔案預設都叫做 pytorch_lora_weights.safetensors 建議改名為 LCM_LoRA_SD15 及 LCM_LoRA_SDXL 容易識別。
檔案下載後放到 models/Lora 再到 LoRA tab refresh 一下就可以見到。
SD 1.5 版本測試
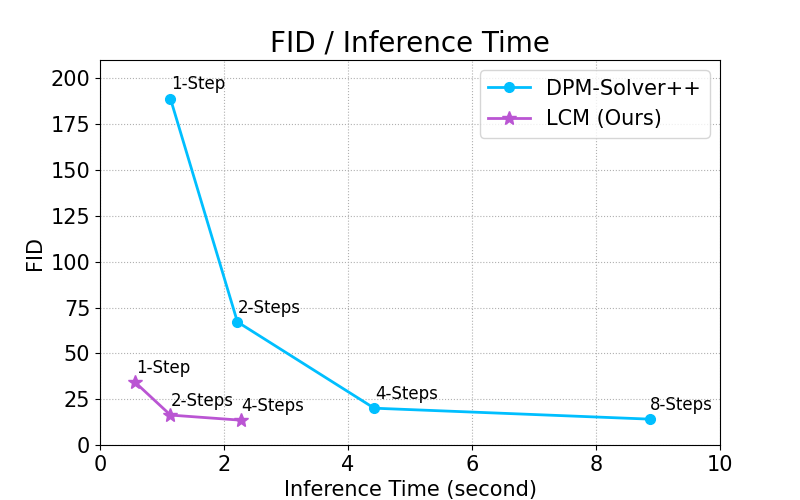
先以官方建議的配置測試一下效果
重點是 Sampling Steps 只有 4 !平是不足以構成圖形的步數,以及超底的 CFP Scale 1.5。

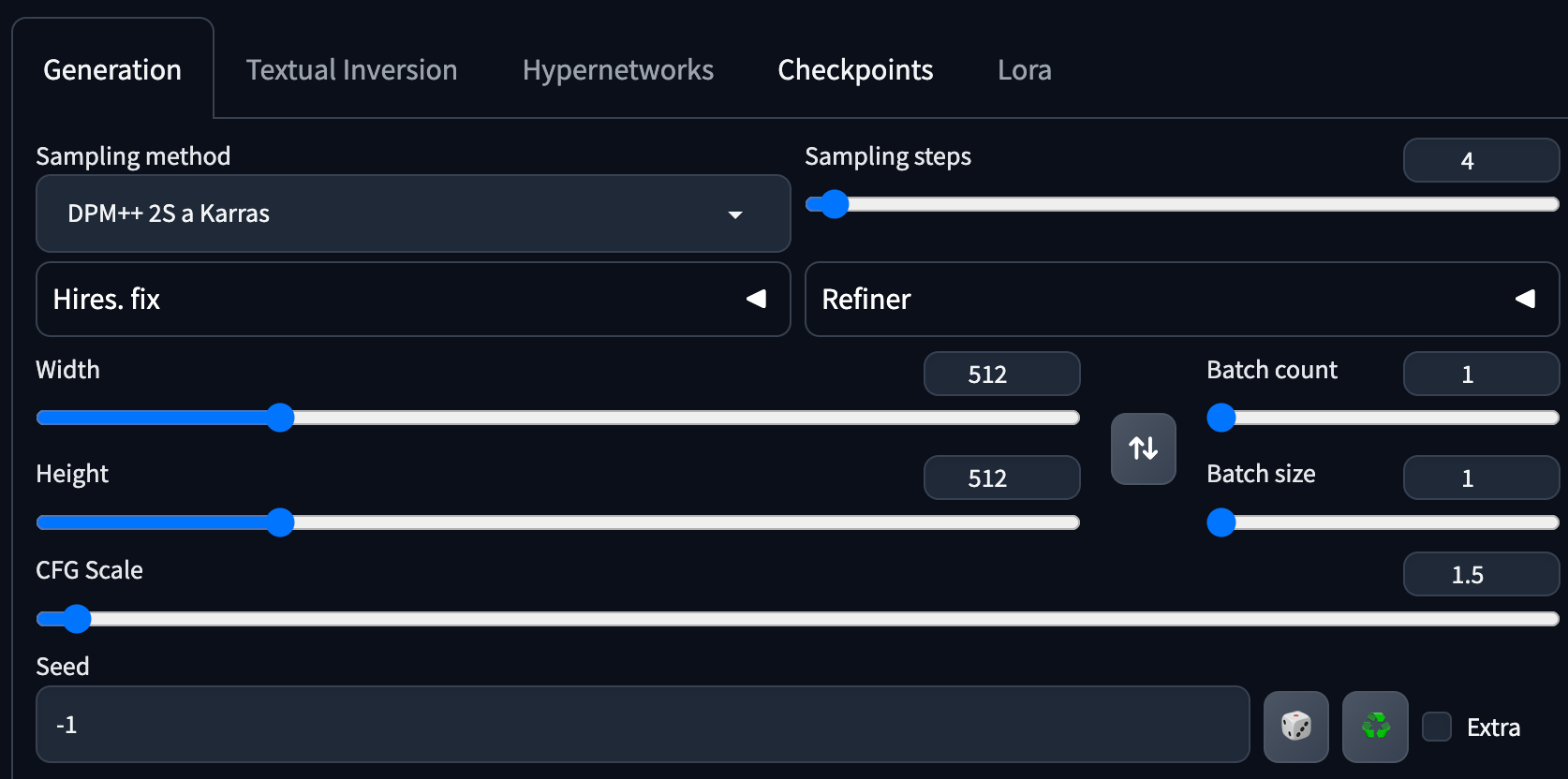
加上簡單的 prompt : (masterpiece, best quality), 1girl, solo, long hair, outdoors, school uniform, day, wind, cloud, looking at viewer, short sleeves, parted lips, shirt, cloud, black hair, sunlight, white shirt, serafuku, upper body, brown hair, blue sky, depth of field, smile, global illumination, <lora:LCM_LoRA_SD15:1>
及 netgative prompt : man, animal, lowres, bad anatomy, worst quality, text, username, watermark, signature, jpeg artifacts, blurry
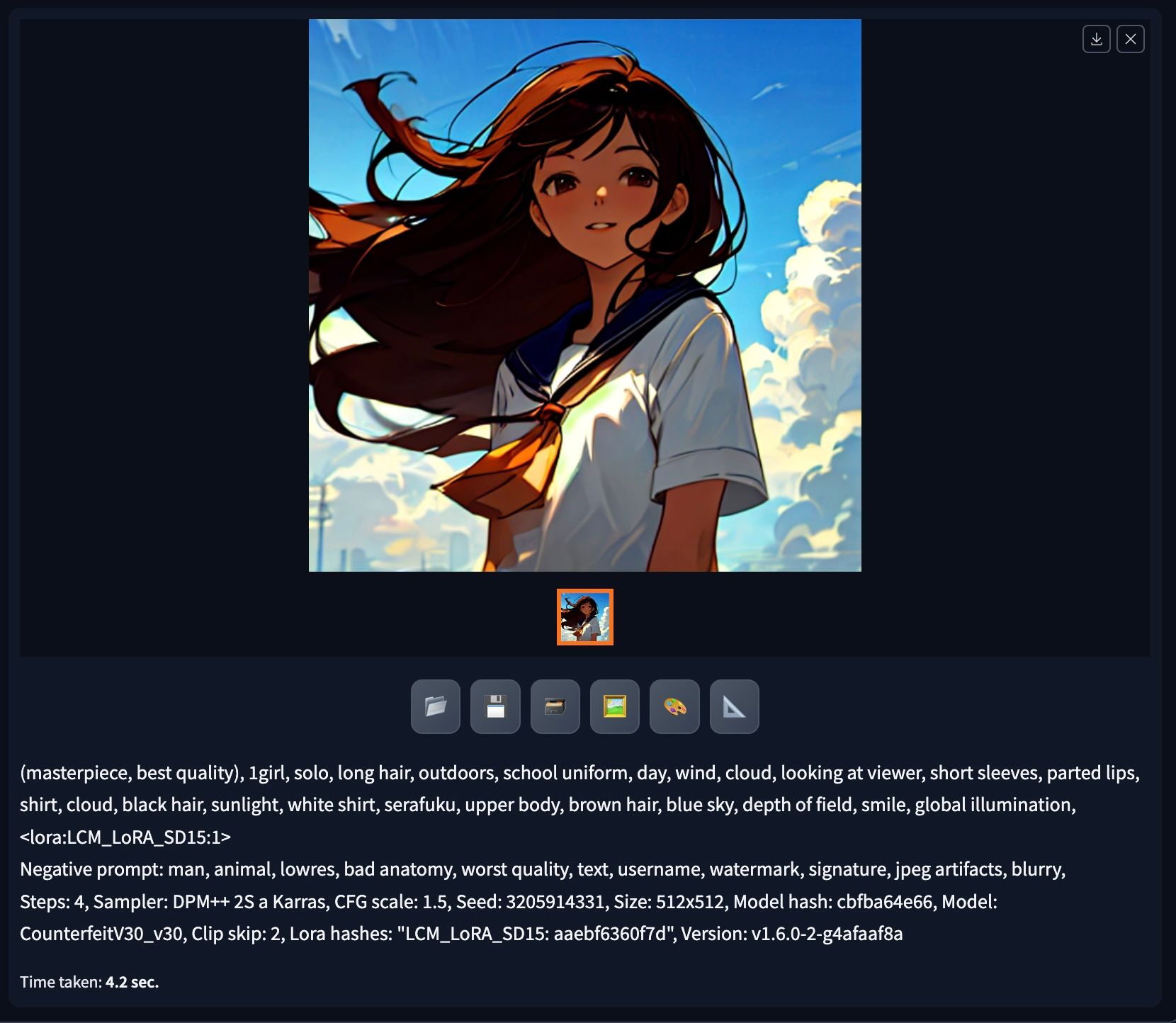
以我的 Macbook Pro M1 32GB 以準,生成四步 512 x 512 的圖只需 4 秒。由於速度很快我就一次成生 12 張看看效果。

雖然不算超精細,但四步來說已經很不錯,那麼跟沒有使用 LoRA 有什麼分別?


在有使用 LCM 的 LoRA 的情況下,第四步人物已經成形,在第十步已經在增加細節。但沒有使用 LoRA 的情況下,第四步時人物依然模糊一片,在第十步才初步成型。
但是聰明的讀者馬上就會發現使用 LoRA 後人物好像整個風格都不對勁。因為 LoRA 權重太高而引起的風格走樣問題,所以我就來測一下不同權重下的分別!

同樣是四步完成,在不同權重下明顯見到了分別,權重越高風格崩壞越強烈,在 0.4 - 0.6 左右對風格影響比較少同時能增加完成度,看大家可以嘗試在步數與權重之間尋找最合適的平衡點。



第一張 8 steps, LoRA:0.5, 第二張 12 steps, LoRA:0.2, 第三張 20 steps, LoRA:0



